DB Suche
Artikel: Besuch bei den Suchprofis der Bahn
Es gibt wahrscheinlich kaum einen Dienst, der im Internet häufiger genutzt wird als eine Suchmaschine. Man ist es gewohnt, dass nach Eingabe eines Suchbefehls viele passende Webfundstücke angezeigt werden. Die Bedienung ist inzwischen so einfach und selbstverständlich geworden, dass sich nur wenige Menschen Gedanken darüber machen, wie komplex die Suche hinter dem Suchschlitz wirklich ist. Darum kümmert sich Markus Schuch. Bei DB Systel arbeitet der Entwickler im Delivery Team „Search & Identity“ und sorgt seit rund zehn Jahren dafür, dass Konzerninhalte per interner Suchmaschine, der sogenannten DB Suche, gefunden werden können. Alle Eisenbahnerinnen und Eisenbahner können mit einem geschäftlichen Endgerät die interne Suche nutzen – egal ob am Computer, Tablet oder Smartphone. Wie auch bei anderen Suchmaschinen klicken Mitarbeiter auf das Eingabefeld und geben den gewünschten Suchbegriff ein, zum Beispiel „Urlaubsantrag“. Während einer Eingabe schlägt DB Suche ähnliche Suchbegriffe mit besonders hoher Relevanz vor. Und obwohl die Nachfrage mit monatlich Zigtausenden Besuchen groß ist, hat die DB Suche ihr Potenzial noch lange nicht ausgeschöpft: Es gibt schließlich immer Möglichkeiten, die Suchergebnisse zu verbessern.
Benutzergruppen mit unterschiedlichen Rechten
Das tolle Ergebnis hat einen langen Weg hinter sich, denn das schnelle Auffinden von Informationen ist besonders in Konzernen sehr komplex. „Suchmaschinen wie die von Google haben es einfacher, da deren Webcrawler öffentlich zugängliche HTML-Inhalte erfassen“, sagt der Spezialist. Websitebetreiber haben ein großes Interesse daran, dass ihre Inhalte gefunden werden. Aus diesem Grund bereiten sie Websites und Daten wie Videos und Bilder so auf, dass Google & Co. die Inhalte verstehen und besser finden. Doch Inhalte in einem Konzern stehen nicht öffentlich zur Verfügung, nur Mitarbeiter haben über das Intranet Zugriff auf die teilweise sensiblen Daten. Mehr noch: Es gibt verschiedene Benutzergruppen mit unterschiedlichen Zugriffsrechten. Darum hat im Konzern niemand ein Interesse daran, für die internen Inhalte eine komplexe Suchmaschinenoptimierung (SEO) zu betreiben. „Auch wir haben es erst einmal mit Webcrawling versucht, aber stießen schnell an Grenzen, weil Inhalte zum Beispiel hinter Logins und versperrten Zugängen lagen“, sagt Markus Schuch. Nur angemeldete Benutzer kommen unter Einhaltung spezieller Konzernrichtlinien an die Inhalte heran. „Wir waren gezwungen, Backend-Schnittstellen zu nutzen, die man sauber absichern kann.“ Das klingt aus dem Mund eines Entwicklers so, als müsste man dafür einfach ein Stromkabel in die Steckdose stecken. Doch ganz so einfach ist es nicht. Um im Bild zu bleiben: Zuerst gilt es herausfinden, was für eine Steckdose in der Wand steckt, welche Kabel zur Verfügung stehen oder welche Signale durch das Kabel laufen bzw. laufen sollen. „Jedes System ist immer etwas eigen, es gibt keine Standardlösungen mit einheitlichen Schnittstellen. Wir müssen dafür immer spezielle Konnektoren bauen.“
Viele Systeme, eine Suche
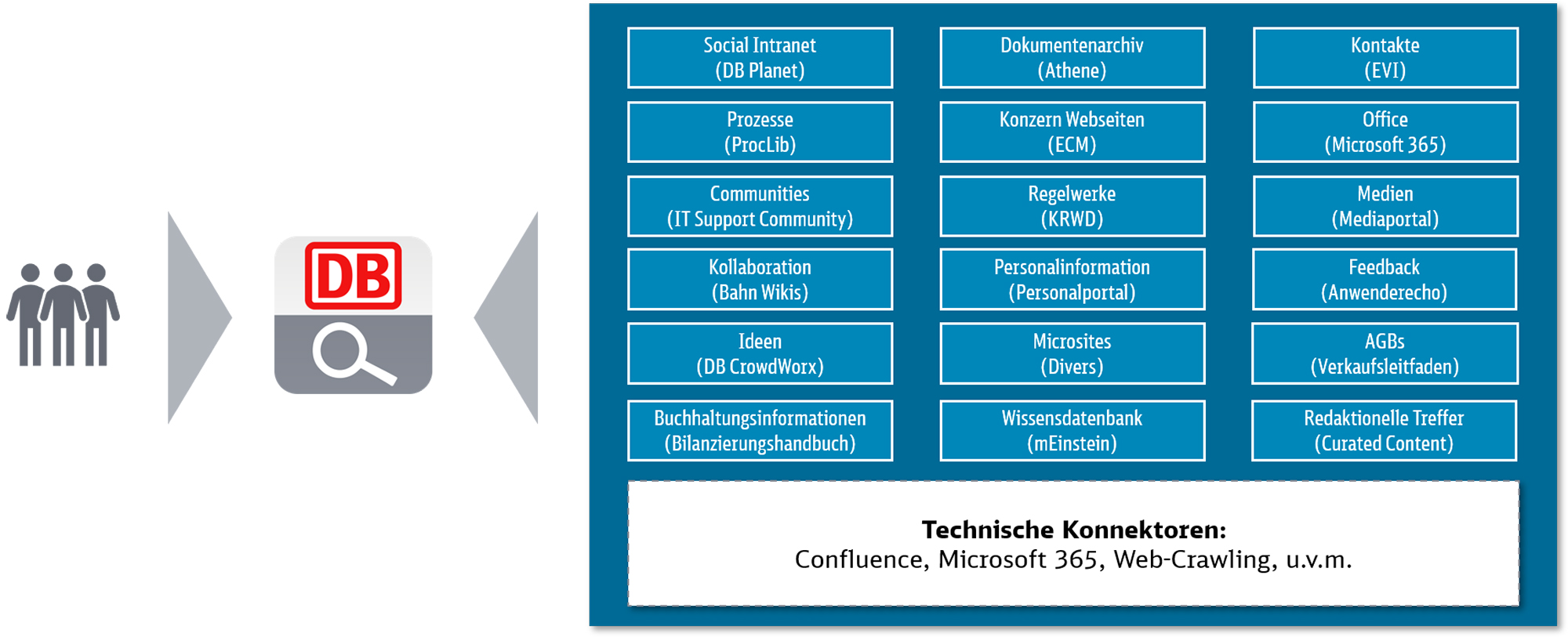
Im Konzern wurden historisch bedingt verschiedene Systeme mit eigenen Suchen genutzt, deren Nutzer kennen die jeweiligen Funktionen. „Aber wenn sie etwas suchen, dessen Ablageort sie noch nicht kennen, haben sie es natürlich schwer“, sagt Markus Schuch. Er weiß, wovon er spricht, denn er hat bei der Bahn schon früh Suchmaschinen mitentwickelt. „Wir haben ein Webcontent-Management-System, mit dem die Websites der Bahn im Internet und Intranet betrieben und gehostet werden. Die haben auch schon immer eine Suchmaschine dabei, jede Website für sich. Als das Team schließlich die Suchmaschine des Karriereportals verbesserte, wurde erstmals mit der Open-Source-Technologie Apache Solr gearbeitet. Auf dessen Basis wurde ein zentraler Suchindex geschaffen. Das System war in der Lage, die Informationen aus bekannten Quellen und internen Datenbanken sowie relevanten Blogs zu ranken und auffindbar zu machen. Bereits der Pilot funktionierte 2013 so gut, dass er schließlich auf alle Konzernmitarbeiter ausgedehnt wurde und immer mehr Quellen angeschlossen wurden, darunter weitere Wikis oder die Konzernregelwerksdatenbank.
Fast zeitgleich kam aus verschiedenen Konzernteilen der Wunsch nach einer einheitlichen Lösung. So machte der Konzern eine Vorstudie zum Thema Enterprise Search, und die DB Systel gab den Impuls zu einer übergreifenden Suche. „Gemeinsam mit unserer Unternehmenskommunikation haben wir einen Prototyp entwickelt und versucht, neben den uns bekannten Websites auch andere Systeme anzuschließen. Während die jeweiligen Systembetreiber einen Zugang zu den Daten erlaubten, entwickelten die Suchexperten passende Konnektoren. Um verschiedene Quellen durchsuchbar machen zu können, mussten die Daten in einem zentralen Index katalogisiert werden.
"Die wichtigste Anforderung bei der Suche ist, dass jeder Benutzer nur die Sachen findet, die er auch sehen darf."

Nicht jede Information ist für jeden Mitarbeiter bestimmt – und nicht jeder Mitarbeiter darf Informationen zur Verfügung stellen. Eine Konzernsuchmaschine muss daher auch bei Suchanfragen und Nutzungen die Berechtigungen überprüfen. „Die wichtigste Anforderung bei der Suche ist, dass der Benutzer nur die Sachen findet, die er auch sehen darf.“ Das klingt einfach, allerdings hat jedes Quellsystem eigene Regeln, wie mit den Benutzerrollen umgegangen wird. „Wir mussten überlegen, wie man Berechtigungen für den Zugriff auf Daten generisch in einem Suchindex speichern kann, um zur Suchzeit die aktuellen Berechtigungen der Nutzer vorliegen zu haben und damit Inhalte filtern zu können.“
Eine Frage der Berechtigung
Die DB Suche durchsucht eine Reihe von Systemen. Dabei wird die Leseberechtigung des jeweiligen Nutzers berücksichtigt. Wie das möglich ist? Vereinfacht dargestellt speichert die Suche die Information, welche Berechtigung für das Lesen eines Dokuments benötigt wird, in einem Feld im Suchindex. Dieser wird etwa alle 24 Stunden erneuert. Dazu werden insbesondere neue, geänderte und gelöschte Dokumente abgefragt und die entsprechenden Zugriffsberechtigungen der Dokumente im Index aktualisiert. Meldet sich ein Benutzer bei der DB Suche an, dann läuft die Maschinerie los und fragt die Quellsysteme, ob es Berechtigungsinformationen zu diesem Benutzer gibt. Diese Informationen lässt die Suchmaschine in die Suchabfrage mit einfließen. So kann zum Zeitpunkt der Suche geprüft werden, für welche Treffer der Suchende leseberechtigt ist. Verliert zum Beispiel ein Nutzer bestimmte Rechte, wird diese Information sehr schnell in der Suche wirksam. Eine Veränderung der Berechtigungssituation eines Dokuments wirkt nach erneuter Indexierung – also spätestens nach 24 Stunden.
Für Markus Schuch ist die Lösung solch komplexer Herausforderungen ein echtes Anliegen. „Wir machen Mitarbeiter und Arbeitsbereiche innerhalb des Konzerns sichtbarer. Wir helfen dabei, dass Informationen besser gefunden und mit Kollegen geteilt werden können.“ Mehr noch: Die enge und vertrauensvolle Zusammenarbeit mit den verschiedenen Konzernteilen und der Zugriff auf interne Datensätze macht auch mögliche Probleme sichtbar. „Bisher wurden Daten in einem System nicht in ihrer Gesamtheit betrachtet.“ Wenn aber Datensätze sinnvoll für die Suchmaschine zusammengeführt werden sollen, müssen alle verfügbaren Metadaten angeschaut werden. Erst dann kann man sie zum Beispiel nach Dateitypen, Autoren oder Datum filtern. Dabei stößt man auch auf Inkonsistenzen in den Daten oder Datenstrukturen, weil durch die Anbindung an die DB Suche zum ersten Mal eine umfassende Sicht auf die Daten erfolgt.
"Im Konzern tragen wir mit unseren Erkenntnissen dazu bei, Ursachen für eine mangelnde Datenqualität nachhaltig zu beheben."
Die DB Suche macht die betroffenen Stellen transparent. Kleinere Inkonsistenzen werden direkt in den Konnektoren ausgebügelt, größere Probleme müssen durch die Anbieter bereinigt werden. „Im Konzern tragen wir mit unseren Erkenntnissen dazu bei, Ursachen für eine mangelnde Datenqualität nachhaltig zu beheben. Die Suche führt zu mehr Datenqualität“, sagt Markus Schuch. Wie gut die Suche im Konzern schon jetzt angenommen wird, wird aber auch dadurch belegt, wie viele Unternehmensbereiche ihre Inhalte damit suchen lassen: DB Suche durchforstet inzwischen rund 80 Prozent der relevantesten Quellen im DB-Konzern, darunter das Social Intranet DB Planet, das Personenverzeichnis EVI, die Konzernregelwerksdatenbank, das DB Managementportal, das Personalportal oder Wikis.
„Starke Suche“
Die DB Suche ist aber nicht nur eine konzernweite Suchmaschine. Als Teil des größeren Projekts „Starke Suche“ ist sie auch ein Zeichen für den digitalen Wandel des Konzerns. Im Rahmen des Konzernprogramms „Starke Schiene“ macht sich die Bahn fit für das digitale Zeitalter. Und das erfordert auch, dass interne Informationen schnell sichtbar und allgemein verfügbar gemacht werden. Darüber hinaus sollen die Mitarbeiter der Bahn auch zügig die externen Informationen finden, die sie für ihre Arbeit benötigen. Aus diesem Grund ist ein weiterer Baustein der „Starken Suche“ die Anbindung der externen Suchmaschine Ecosia. So hat die Starke Suche einen weiteren positiven Effekt: Die nachhaltige Suchmaschine verwendet die erzielten Einnahmen, um in mehr als 15 Ländern Bäume zu pflanzen. Echt stark, so sorgt DB Suche nicht nur innerhalb des Konzerns für gute Ergebnisse.



 Weiter
Weiter